Connect External BI System
 In today's fast-paced business environment, data
reigns supreme. The ability to gather, analyze, and leverage data effectively can make all the difference between thriving
and merely surviving.
In today's fast-paced business environment, data
reigns supreme. The ability to gather, analyze, and leverage data effectively can make all the difference between thriving
and merely surviving.
This is where Business Intelligence (BI) systems come into play, providing organizations with invaluable insights to drive strategic decisions and enhance your seller's performance.
By leveraging the combined power of the Showpad platform and the analytical prowess of BI systems, organizations can gain a deeper understanding of its sales processes, customer behavior, and content effectiveness.
Classic Situation
A company wants to combine its Showpad data with the data in its BI tool. This is generally a tedious manual process requiring them to:
- Export their data from Showpad
- Load the export into their data warehouse
- Transform the data
- Prepare/optimize queries
- Enrich with company-specific data
- Combine the data in their BI tool
- Create visualizations
With so many manual steps, the scene is ripe for errors and data contamination. They want to automate this integration to expedite insights generation and decision-making and optimize their sales strategies and operational efficiency.
An automated approach ensures that Showpad data seamlessly merges with their BI tool's dataset, empowering the company to harness a comprehensive view of their sales performance without cumbersome manual interventions.
Keep reading to see how Showpad simplifies this process.
SharePoint & PowerBI Example
- Plan: Ultimate | Advanced or Expert
- Permissions:
- Administrator access to Showpad's Admin App
- Administration rights to SharePoint and PowerBI
A Sharepoint integration enables you to continuously update your Showpad usage data with the Power BI service without additional infrastructure or software. You only need a publicly accessible Sharepoint.
The architecture for this setup looks like:
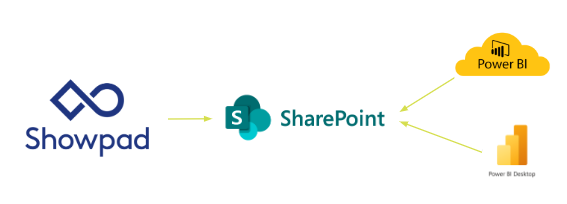
The major steps of the flow are:
- From Showpad, create daily ETL script to create CSV exports.
- Upload export files to SharePoint.
- Stage the data with incremental refresh (daily job) with the Power BI Service
- Use PowerBI service datastores for dashboards etc.
It typically looks like this:
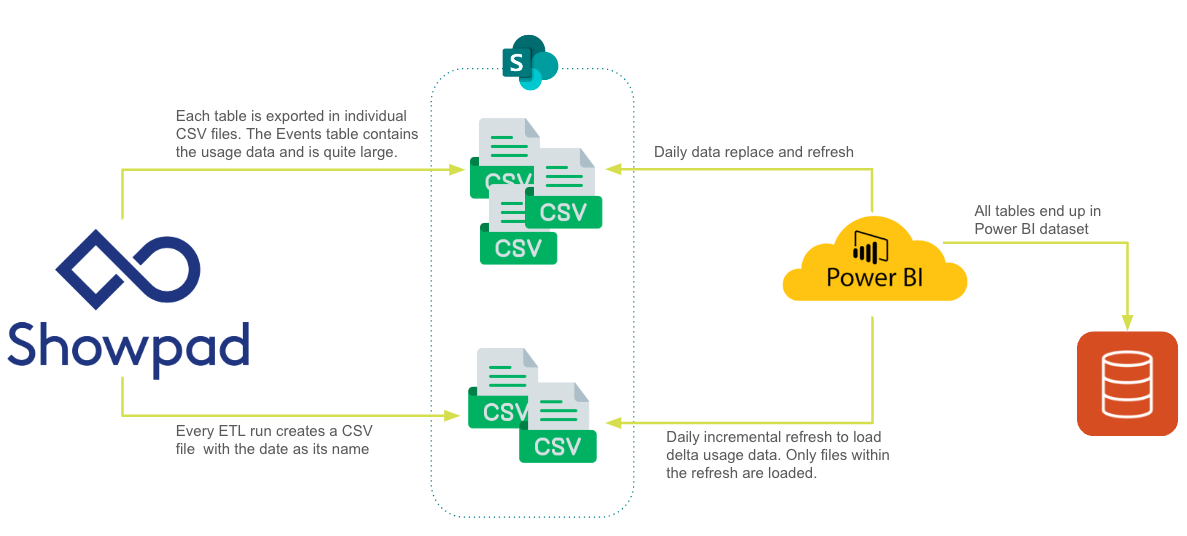
Things to keep in mind:
-
Export all tables in CSV format.
-
The Events table will be very large. It's important that you consider incremental exports and how to incrementally update your BI events table. This is important for both exporting the data as well as for staging your files.
-
We recommend running an export once a day, always fetching the last full day.
-
Be sure to pay attention to time zones!
-
Name the Events CSV export file with the end date of the export range. Example:
├── assetAuthors.csv
├── assetCountries.csv
├── assetLanguages.csv
....
├── events
│ ├── 2023-08-06.csv
│ ├── 2023-08-07.csv
│ └── 2024-03-13.csv
.....
The following sections demonstrate the essentials of connecting Showpad with a SharePoint data warehouse and PowerBI. Please note that this is not a complete step-by-step tutorial.
Showpad
-
If you don't already have SharePoint integrated with Showpad, open the Admin Settings of the Online Platform and enable a SharePoint integration. This article on our Help Center will walk you through it. You may need to collaborate with your Showpad admin.
-
Develop and configure a managed ETL script to extract Showpad data from Showpad API. Here are some helpful example queries to get you started.
For your synchronization script (see code example below), we recommend:
- Determine the last run date to calculate logged before / logged after parameters
- Download events usage data
- Download the other 21 tables from showpad to the disk
- Upload them afterward to Sharepoint (in chunks)
For exporting the Events table:
-
Export sync:
-
Here's a helper function to store the incremental results on disk. Without something like this, you run the risk of running out of memory.
-
Here's a script to bring it all together:
All other tables can be exported without needing an offset or scrollId:
SharePoint & PowerBI
SharePoint
-
Because you're the resource owner, we recommend using Sharepoint’s Client Credential flow.
-
Next, you must upload your Showpad CSV export files to SharePoint. We recommend replacing all tables except the Events files.
Upload the Events data to SharePoint in chunks to avoide the API failing due to artifacts that are too big.
PowerBI
Before using the CSV data, you need to use some PowerBI Desktop features to load and transform the data.
| Parameter | Data Type | Description |
|---|---|---|
RangeStart | Date/Time | The starting date to fetch the Events CSV files from SharePoint by date. This exact name is expected in the PowerBI service for the incremental refresh. Example 1/1/2020 12:00:00 AM |
RangeEnd | Date/Time | The ending date to fetch the Events CSV files from SharePoint by date. This exact name is expected in the PowerBI service for the incremental refresh. Example 1/1/2023 12:00:00 AM |
SharepointSiteUrl | Text | URL to your SharePoint site Example https://showpad365.sharepoint.com/sites/showpadUsage |
projectRoot | Text | Name of the folder where your CSV export files are stored. Example export_data |
-
Upload files
-
All tables except Events
The following code snippet (Advanced Query) loads theusers.csvfile from your SharePoint via the Sharepoint Connector and creates a table. We recommend building one query per table / .csv file. -
Events table
As the Events table grows, we recommend incrementing the usage data instead of fully loading the entire table. This is the reason behind creating one CSV file per export and name the file with theloggedBeforedate.
-
-
Transform files
The following helper function/query will load the csv binaries within the date ranges. -
Incremental refresh settings
Once the Events table is created, you need to adjust the incremental refresh setting before pushing this to the PowerBI service. Here, you define theRangeStartandRangeEndvalues the service will populate for the initial and incremental loads.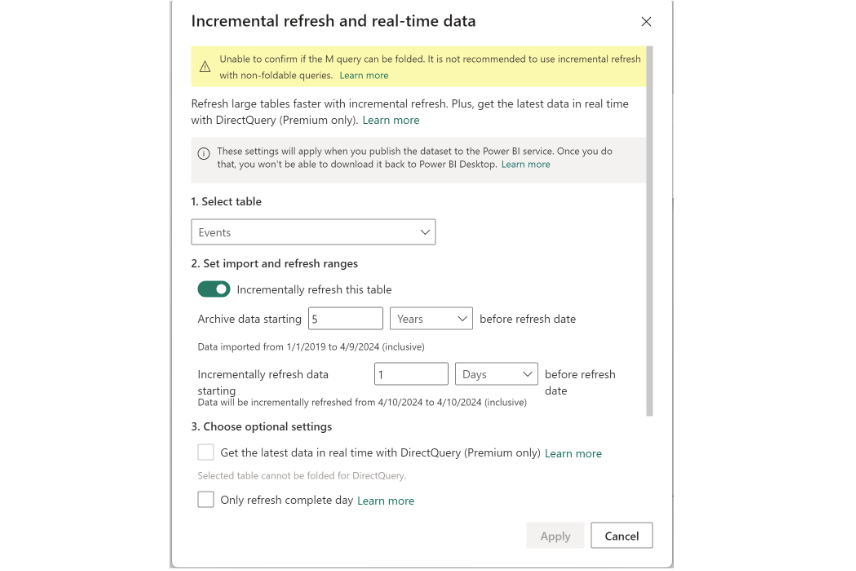
-
Create incremental refresh
The last step is to define the incremental refresh for all tables. It's essential to run them on a daily basis.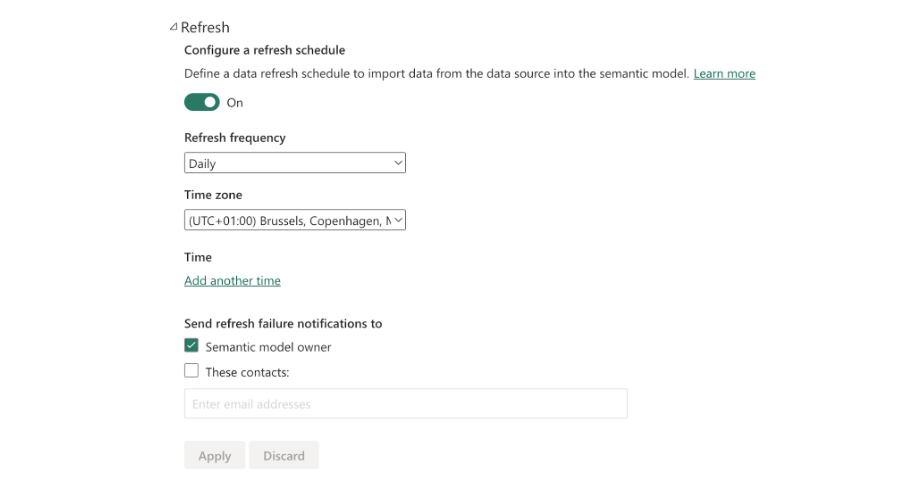
And that's it! Once you've got everything set up and running smoothly, valuable insights from your own custom analytics are at your fingertips .
If you need assistance connecting your BI system to Showpad, please reach out to Showpad.
Was this page helpful?